Analytics is about finding meaningful patterns in data. Real-time analytics is about building patterns by analyzing events as they occur. Traditional analytics is based on offline analysis of historical data, whereas real-time analytics involves comparing current events with historical patterns in real time, to detect problems or opportunities.
For example, in telecom when a subscriber uses a service on his/her terminal, it results in data exchange with his/her service provider. Typically, the telecom service provider just provides the requested service and stores charging data for billing / future reconciliation purpose. Here, real time analytics provides an opportunity to create value-added applications by processing these incoming data streams. These value-added applications can track the quality of service offered to its subscribers, in real time. The service provider can see how many of its subscribers are experiencing problems with data connectivity and call drops. In real time, the service provider can investigate the root cause of most of the problems. With few mouse-clicks, it can find out whether it is due to poor coverage or network congestion or a misfit service plan or it is a problem due to subscriberís terminal. This insight can help the service provider to take corrective actions in real time. The service provider can address the issues with coverage and congestion proactively, before complains start pouring in. Similarly, it can offer a more appropriate service plan or terminal to its affected subscribers, which can improve their overall experience.
Big data technologies enable us to process data in large volumes as well as high velocity. Technologies like Hadoop makes it possible to run batch-oriented analytics over terabytes of data. Similarly, technologies like Apache Storm enable us to develop run-time analytics solutions which can process thousands of messages per second. Apache Storm helps us address the challenges of developing a reliable distributed solution such that our development effort is focused on business logic rather than implementing a distributed platform.
Business Challenges
Traditionally, in an incoming service request we avoid additional processing. For example the processing which is required to look for patterns and statistics. Especially, when rate of the incoming data stream is of the order of thousands messages per second because any delay introduced by the additional processing can result in bottleneck in service delivery. Such delays can trickle down to impact on quality of service.
For example, in telecom, a service provider may have complete details of each service taken by each of its subscribers. However, a service provider may have subscribers in order of 1,000,000s and analyzing service problems in real-time may require capability of processing 1,000s of messages per second (considering the aggregate traffic generated by these subscribers during a busy hour). Moreover, the system may also have to analyze performance data reported from the network infrastructure itself.
To handle such a high rate of incoming data, solution would typically require distributed computing and high availability. Traditional solutions for building these clusters and managing them are expansive and require good amount of maintenance effort. Besides, a traditional distributed solution has its own set of challenges like trading off between reliability and performance.
Traditional Approaches and its Disadvantages
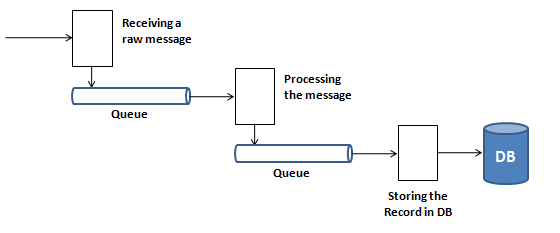
Traditionally, real time processing is done using queues and workers. For example, first there is a worker to receive messages and to place it in a queue. Second worker listens to the queue, picks up the message, parses it, processes it and places the processed message in a second queue. Next worker picks up the processed message from the second queue and logs it in database.
This approach has several disadvantages. First, it needs to be made sure that all queues and workers stay up, all the time. Secondly, when application is required to scale to support high throughput, then these queues and workers are required to be distributed. Distributing the queues, requires exchange of state across all the nodes within the cluster and there is a trade-off between reliability and performance of the distributed queues.
Distributed queues and fault-tolerance are complex functions. Implementing life cycle management of the queues (setting up, monitoring, cleanup, setting-up again) involves significant development time. Especially, fault tolerance and high-availability require good amount of development time and their maintenance is also quite expensive. Usually, these functions cannot be tested in lab environment because problems appear only in high load conditions. Moreover, when these problems occur in field, then one does not get debug-traces for troubleshooting. In short, it will be a great relief if an off-the-shelf framework can provide distribution and fault tolerance along with high performance, for real time processing.
Apache Storm
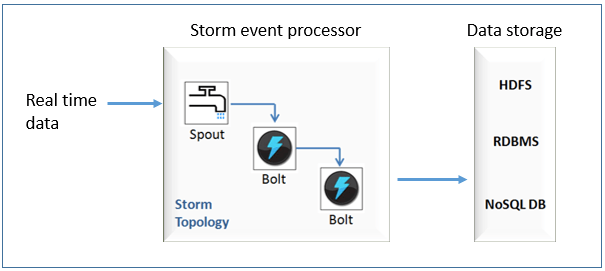
Apache storm is a framework that facilitates distributed real-time processing. Real-time processing of a data stream with Storm, is like water treatment of a stream of water. The way stream of water is taken through various stages, different procedures are performed in each stage and output of one stage is fed as input to the next stage. Similarly, during real-time processing of a stream of data by Storm, a spout reads the incoming data stream and feeds it to a processing unit called bolt. Bolt performs specified business logic on the data stream and passes on the processed stream to the next bolt. Bolts and interconnections between them are termed as storm topology. There can be one or more topologies in a single system, which can be connected through message queues.
Each spout and bolt can have one or more instances. These instances can be spread throughout the storm cluster. Communication among these distributed spouts and bolts is transparent to a developer. The communication is seamlessly managed by the storm framework itself. Storm is open-source and is available free-of-cost (https://storm.apache.org/about/free-and-open-source.html). To use Storm, a developer is primarily required to provide implementation of execute() method of each bolt. Following features come out-of-the-box with Apache Storm:
Distributed framework (scalable)
Fault tolerant (highly available)
Guarantees no data loss (reliable)
Storm topology can be easily integrated with different data storage options, like HDFS, traditional RDBMS, and a NoSQL database.
Real-Time Analytics With Network Data
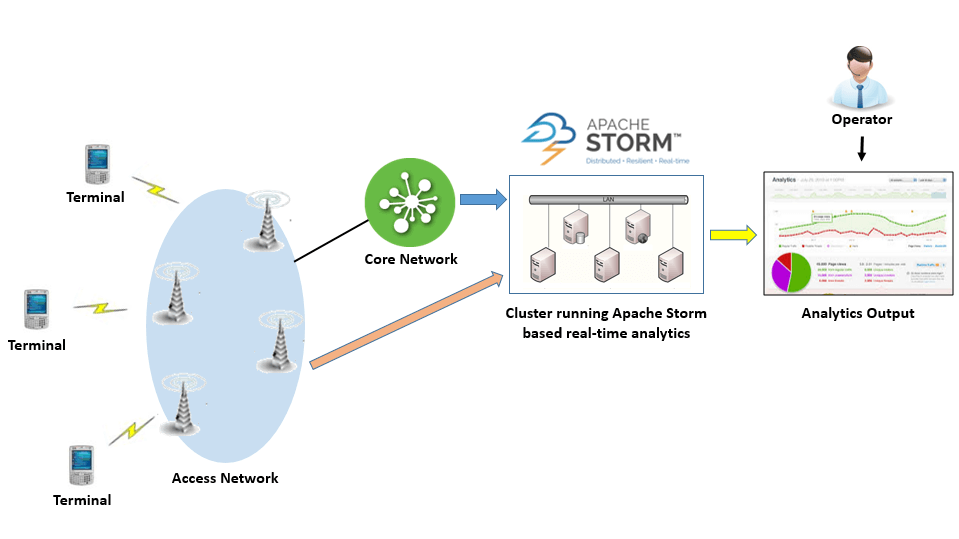
This section explains Apache Storm based real-time analytics solution, using an example of a telecom service provider. In the network of a telecom service provider, there can be different sources of incoming data, like:
Stream of data generated due to use of services by subscribers
Performance data of access network, as reported by network probes
Data related with new subscription orders, activation and terminate orders
A single storm topology running inside a cluster can listen to all different kinds of incoming data. The storm topology may have different spouts for each source of input. Spouts are followed by Bolts which take care of processing the incoming data and calculate statistics which captures information across services, regarding the quality of service provided to the subscribers, performance of network elements and new received orders. The processed statistics are stored in a NoSQL database for future reference and are also used to plot several services-related real-time charts.
The analytics can be used to device a solution that can automatically detect under-performing network elements and reconfigure the network such that it is more balanced with respect to its utilization. Similarly, network coverage related issues can be tracked and input can be provided to network planning, in real-time. Also, the analytics charts can be monitored by proactive call center operators, who can reach out to subscribers (who are facing service related issues) with attractive offers to replace their service plan or terminal which suits better to their usage pattern.
Such seamless handling of network-related issues and proactive customer support can be instrumental in improving user experience manifold. It can help a telecom service provider in building a competitive advantage in the market, by maintaining a real-time focus on customer experience.
Apache Storm provides a stable and robust framework for a real-time analytics solution. The framework provides base classes for spouts and bolts. Spout class inherits class BaseRichSpout and bolt class inherits BaseRichBolt. One is required to just implement nextTuple() method in spout class such that it reads data from an incoming data stream and emits it inside the storm topology. Similarly, one has to write the implementation of execute() method in bolt class to provide business logic to process the data passed on by the connected spout. Multiple spouts can be defined for different sources of data. For example, one spout for tapping into charging data, second to tap performance data from the access network and third spout for accessing data from incoming order requests.
Conclusion
In short, it is a collection of spouts and bolts (interconnected with each other) which is referred to as storm topology. Business logic to process the incoming stream of data is embedded within this topology. Storm framework distributes this topology across different nodes of the cluster and ensures reliability along with high throughput (off-the-shelf). This way development remains focused on the business logic of the data processing.
References
Apache Software Foundation,ìRationaleof using ApacheStorm, https://storm.apache.org/documentation/Rationale.html,2014
Nathan Marz, History of Apache Storm and lessons learned, https://nathanmarz.com/blog/history-of-apache-storm-and-lessons-learned.html,Thoughts from the red planet,6th October 2014.
Thank You!
Thank you for contacting us. We will get back to you soon.
X
We will get back to you!
Thank You!
Thank you for contacting us. We will get back to you soon.
 Product Engineering Services Customized software development services for diverse domains
Product Engineering Services Customized software development services for diverse domains