
Virtual Network Functions are a new trend in the architecting of network services. In VNF terminology, a single network function is decomposed into multiple modules or services, which are then deployed using a combination of virtual machines and cloud deployment, under the control of an orchestration solution such as Openstack, typically deployed over an SDN networking infrastructure. By disintegrating the service into micro-services and then using sophisticated mediation, orchestration and scaling services, the network operator can have optimal allocation of both computing and networking resources.
In this context, the specific task of decomposing the end-to-end network service into micro-services is an interesting challenge. As identified in [vEPC], many, especially in the telecom arena does not have the luxury initially of doing a green-field design, which would entail significant re-design of the inter-module APIs. Rather, existing solutions are being retrofitted into the architecture, by suitable configuration of the orchestration platform.
Broadly, microservice architectures tend to take one of two forms. Web-services are typically built using horizontal integration. In this model, standalone services integrate with each other to provide sub-services in a top-level service. An example is given in [Backtory], where the authors create a chat service out of a combination of services for social media profiling, chat hosting, email integration, etc. The micro-services don’t directly talk to each other; rather a top-level coordination ensures that they work together to provide an end-to-end service
On the other hand, the emerging field of Network Function Virtualization typically tends to use a vertical integration approach. In this method, modules are composed in a chain, where only the first and last entities in the chain are in direct contact with the outside world. Intermediate entities pass information to each other to provide a complete end-to-end function. The chains are composed directly by the orchestrator using separately configured VNF forwarding graphs. Challenges in this kind of architecture include scaling, end-to-end latency challenges, etc.
Both the vertical and horizontal integration views are functional views. They see end-to-end services as a sequence or combination of functions. In the following two use cases, we offer a different data oriented view. We then show how we can integrate the data service part using a new data sharing architecture, we call ‘Publish-Subscribe-Consume’ (Pub-Sub-Cons). We have introduced a new entity, the data-bucket which acts as a repository, monitor and trigger point for initiation of specific activites. The data-buckets themselves are virtualized entities of a specific type.
A simple use case is that of video-stream analysis. We have a two step video stream analyzer, which analyzes, for example, a CCTV feed, searching for faces to match against a known whitelist. The analysis happens in two steps; in the first step, a process scans the frame for ‘face like’ structures; if [N milliseconds] of continuous video feed have the same ‘face like ‘ structure in them, it marks the associated segment and corresponding meta-data. Subsequently a second stage is triggered which collects the face image from the entire segment and matches it against the whitelist of facial images available to it.
In this scenario, that the triggering of the second step is conditional. Further, there is a step between processing of step 1 and processing of step 2, where the intermediate data has to be collected. In our architecture, this functionality is provided by the data-bucket. The data-bucket starts collecting data output by the step 1, when the ‘facial structure’ is detected; it holds data till a sufficient amount is collected and then passed it on to an instance of the second step processing. Conditions in between may cause a premature termination; for example, the feed terminates before sufficient data is collected. In this case, the data-bucket entity can clean out its repository and initialize itself.
A second, more complex case is that of IoT. We imagine a scenario where there is a wide-spread network of IoT sensors. The sensors are of two categories; a net of primary sensors whose reading is constantly monitored and a net of secondary sensors, whose readings are used to take action if the primary sensor is out of range. The secondary sensor network publishes their readings into the IoT network; however, there is no action on it unless the primary sensor reading triggers it. Yet, the secondary sensors cannot hold onto the data indefinitely; nor can they be queried at the time of need.
In our architecture, the data from the secondary sensor is published into the IoT network, where it is stored by a network of data-buckets, which have subscribed to this data. The data-buckets perform the necessary curation of data (replacing stale data by new values, etc.). When the condition for consuming this data becomes true, the corresponding application function can then consume this data and empty the bucket.
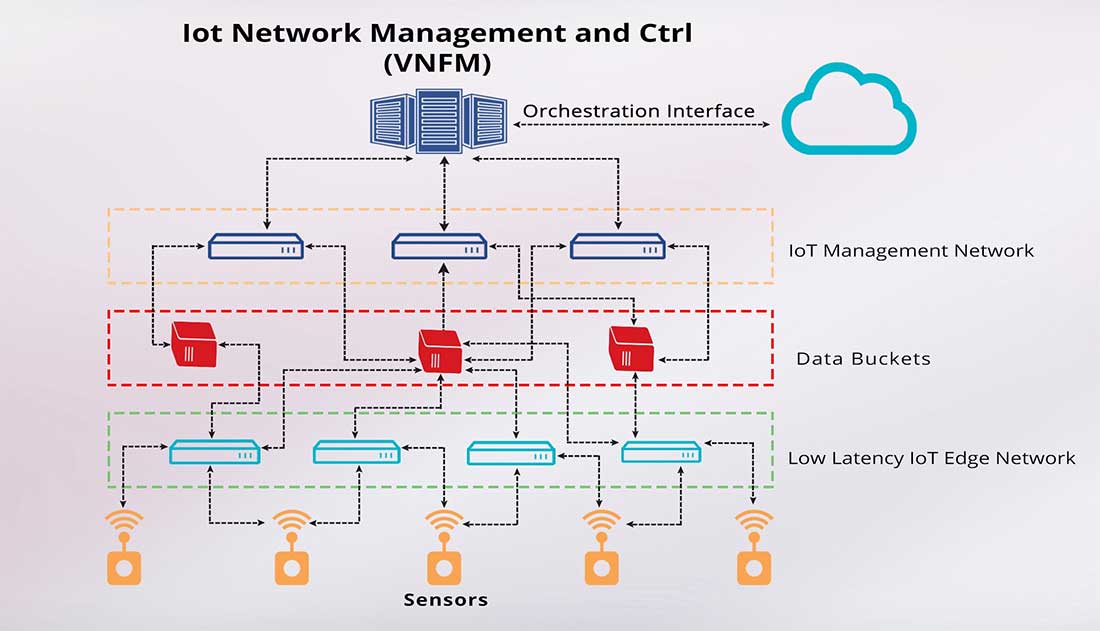
The key concept introduced in the Pub-Sub-Cons architecture is the data-bucket. A data-bucket is an independent network of entities which are set up as part of the network definition process. Along with the standard set of rules provided for instantiation of processes and definition of the underlying network, we also create a set of definitions for data-bucket categories. The orchestration manager is extended to recognize data-buckets as a unique class of entities and create process instances/netwoke definitions for the same.
Data buckets are defined by a set of subscription rules and a set of rules for managing the data. The subscription rules define the set of data to be subscribed to and the set of management rules define the images to be activated when a specific condition is triggered. Rules may be defined for cleaning data, reconciling with other data-buckets and activating the consumer process. The example below shows a data-bucket which maintains two repositories and has one rule which is invoked when the first repository is full or the second one has at least 10 entries.

The specific realization of a data-bucket can take many forms, depending on the size and the extent of the network. Specifically, the following must be taken into consideration.
In a mobile edge environment, we anticipate that data-buckets should be placed within the Local Area Data Network. However, unlike the MEC case, the data-buckets have to be discoverable by each other and the VNFM outside, since the data is eventually consumed by applications running in the core.
The implementation of the data-bucket is integrated with the orchestration logic which manages the compute processes. The data-bucket may instantiate multiple processes based on its internal logic; these processes will be instantiated either as containers/VMs or as Cloud instances; in either case, the appropriate integration is done with the orchestration logic through a common API.
The data-bucket uses a distributed Publish-Subscribe mechanism which is made available as a platform with standard APIs. A large network may have multiple data-bucket instances; the number of data buckets need to scale based on the number of entities and the configuration. SDN is used as a way to distribute traffic from the publishing entities (which have no knowledge of the specific identity or location of the subscribers) to the subscribing data-buckets.
The SDN paradigm is also useful for slicing the networking so as to separate the edge to data-bucket, inter-data-bucket and the data-bucket to core connectivity. The three networks have to be designed with different characteristics.
Finally, the data-bucket to core network must support a gather-read/scatter-write implementation paradigm, where core applications can support associative and content based searches.



